Hi everyone, inside this article we will see the concept about Basics of Trees Algorithms.
In computer science, a tree is a data structure composed of nodes connected by edges, with each node having a parent node and zero or more children nodes. Trees are often used to represent hierarchical relationships between elements, such as the structure of a file system or the organization of a company. They are also used in algorithms for searching, sorting, and optimization.
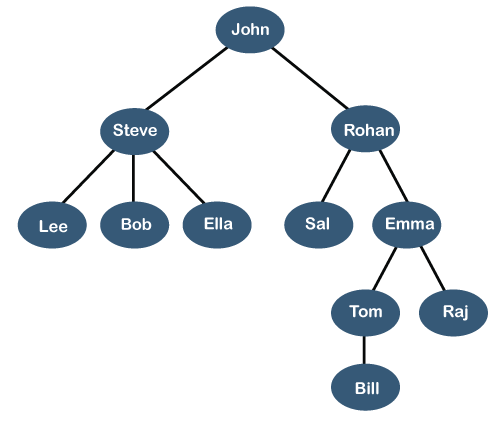
Trees are commonly used in algorithms and data structures due to their ability to efficiently represent hierarchical relationships.
Key Points of the Tree Data Structure
Here are some key terms that are commonly used in the context of trees in data structures and algorithms:
- Node: A node is a fundamental element of a tree, which contains a value or data, and pointers to its child nodes.
- Root: The root node is the topmost node in a tree, and it has no parent node.
- Parent: A node that has one or more child nodes is called a parent node.
- Child: A node that has a parent node is called a child node.
- Leaf: A leaf node is a node that has no child nodes.
- Depth: The depth of a node is the number of edges from the root node to that node.
- Height: The height of a node is the number of edges on the longest path from that node to a leaf node.
- Subtree: A subtree is a portion of a tree that is itself a tree, which consists of a node and all its descendant nodes.
- Binary tree: A binary tree is a tree data structure in which each node has at most two children.
- Binary search tree (BST): A binary search tree is a binary tree in which the left subtree of a node contains only nodes with values less than the node’s value, and the right subtree contains only nodes with values greater than the node’s value.
- Balanced tree: A balanced tree is a tree in which the heights of the left and right subtrees of each node differ by at most one.
- Traversal: Traversal refers to the process of visiting all the nodes in a tree in a specific order.
- Pre-order traversal: In pre-order traversal, we visit the root node first, then recursively traverse the left subtree, and then the right subtree.
- In-order traversal: In in-order traversal, we recursively traverse the left subtree first, then visit the root node, and then recursively traverse the right subtree.
- Post-order traversal: In post-order traversal, we recursively traverse the left subtree first, then recursively traverse the right subtree, and finally visit the root node.
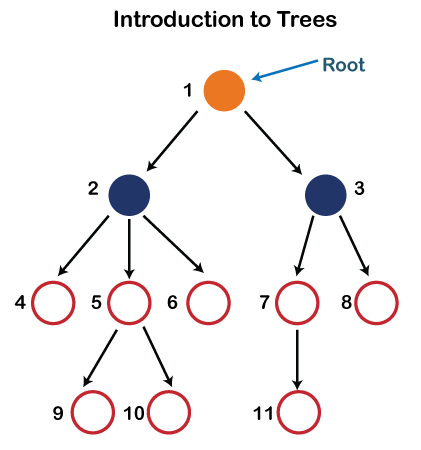
These are some of the key terms that are commonly used in the context of trees in data structures and algorithms. Understanding these terms is essential for working with tree data structures and developing tree-based algorithms.
Usage of Trees Algorithms
Tree algorithms are commonly used in computer science for a variety of tasks, including:
- Storing and searching data: Trees are often used to store data in a way that allows for efficient searching and retrieval. Binary search trees, AVL trees, and red-black trees are commonly used for this purpose.
- Parsing and manipulating text: Tries and suffix trees are commonly used for parsing and manipulating text. Tries are particularly useful for implementing autocomplete features in text editors and search engines.
- Implementing file systems: B-trees and B+ trees are commonly used for organizing and storing files in file systems. They allow for efficient retrieval and modification of files stored on disk.
- Implementing network routing algorithms: Trees are often used to implement network routing algorithms. For example, spanning trees can be used to find the shortest path between two points in a network.
- Game AI: Trees can be used to implement game AI algorithms, such as decision trees and minimax trees. These algorithms are used to make decisions and select the best moves in games like chess and checkers.
Overall, tree algorithms are a powerful tool for solving a wide variety of problems in computer science. By organizing data in a hierarchical structure, trees can provide efficient access and manipulation of large amounts of data.
Types of Tree Algorithms
There are many types of tree algorithms in computer science, each with its own strengths and weaknesses. Here are some of the most commonly used types of tree algorithms:
- Binary Search Trees (BSTs): BSTs are a type of tree data structure that is used to store and search data in an ordered manner. In a BST, each node has at most two children, with nodes in the left subtree having values less than the root and nodes in the right subtree having values greater than the root.
- AVL Trees: AVL trees are a type of self-balancing binary search tree that maintains a balance factor for each node. The balance factor is the difference between the heights of the left and right subtrees. AVL trees use rotations to maintain the balance of the tree and keep it height-balanced.
- Red-Black Trees: Red-Black trees are another type of self-balancing binary search tree that use a set of rules to maintain balance. In a Red-Black tree, each node is either red or black, and the tree is balanced such that no path from the root to a leaf node is more than twice as long as any other path.
- B-trees: B-trees are a type of self-balancing tree that are designed to efficiently store and retrieve data from disk or other secondary storage devices. B-trees are commonly used in databases and file systems.
- B+ trees: B+ trees are a variant of B-trees that are optimized for use in databases. In a B+ tree, all the data is stored in the leaf nodes, while the internal nodes contain only keys. This makes B+ trees efficient for range queries and sequential scans of data.
- Trie: Trie is a tree data structure that is used to store strings and allows for efficient prefix-based searching of strings. Each node in the trie represents a prefix of a string, and the child nodes represent the possible next characters in the string.
- Segment Trees: Segment trees are a type of binary tree that are used to efficiently answer range queries over an array or other data structure. Segment trees can be used to perform operations like finding the sum of elements in a range or finding the minimum or maximum element in a range.
These are just a few of the many types of tree algorithms that are used in computer science. Each type has its own unique properties and is suited to solving different types of problems.
We hope this article helped you to understand Basics of Trees Algorithms in a very detailed way.
Online Web Tutor invites you to try Skillshike! Learn CakePHP, Laravel, CodeIgniter, Node Js, MySQL, Authentication, RESTful Web Services, etc into a depth level. Master the Coding Skills to Become an Expert in PHP Web Development. So, Search your favourite course and enroll now.
If you liked this article, then please subscribe to our YouTube Channel for PHP & it’s framework, WordPress, Node Js video tutorials. You can also find us on Twitter and Facebook.